Introducing VerifAI's MultiLLM framework
Harnessing the power of Multiple Large LLMs
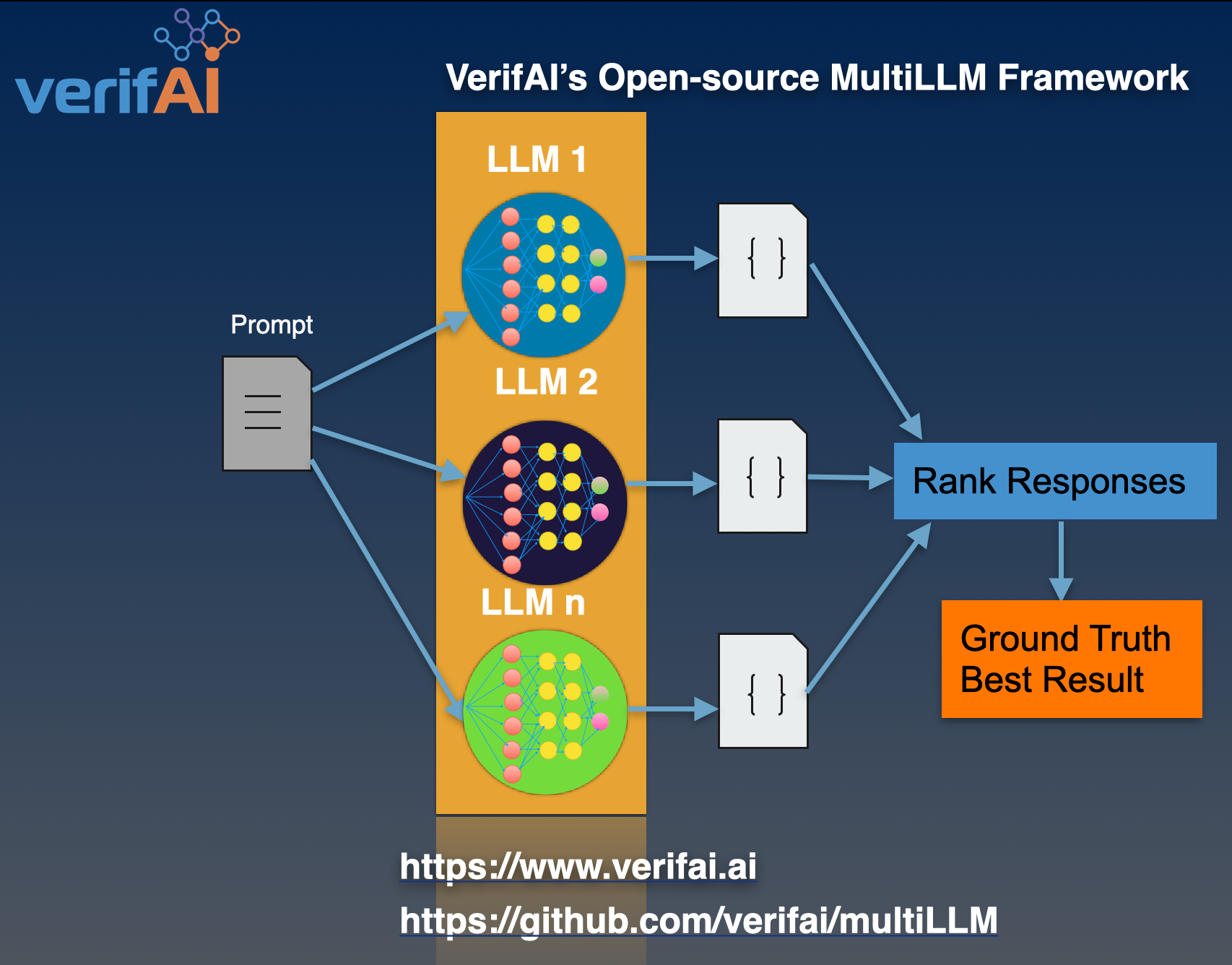
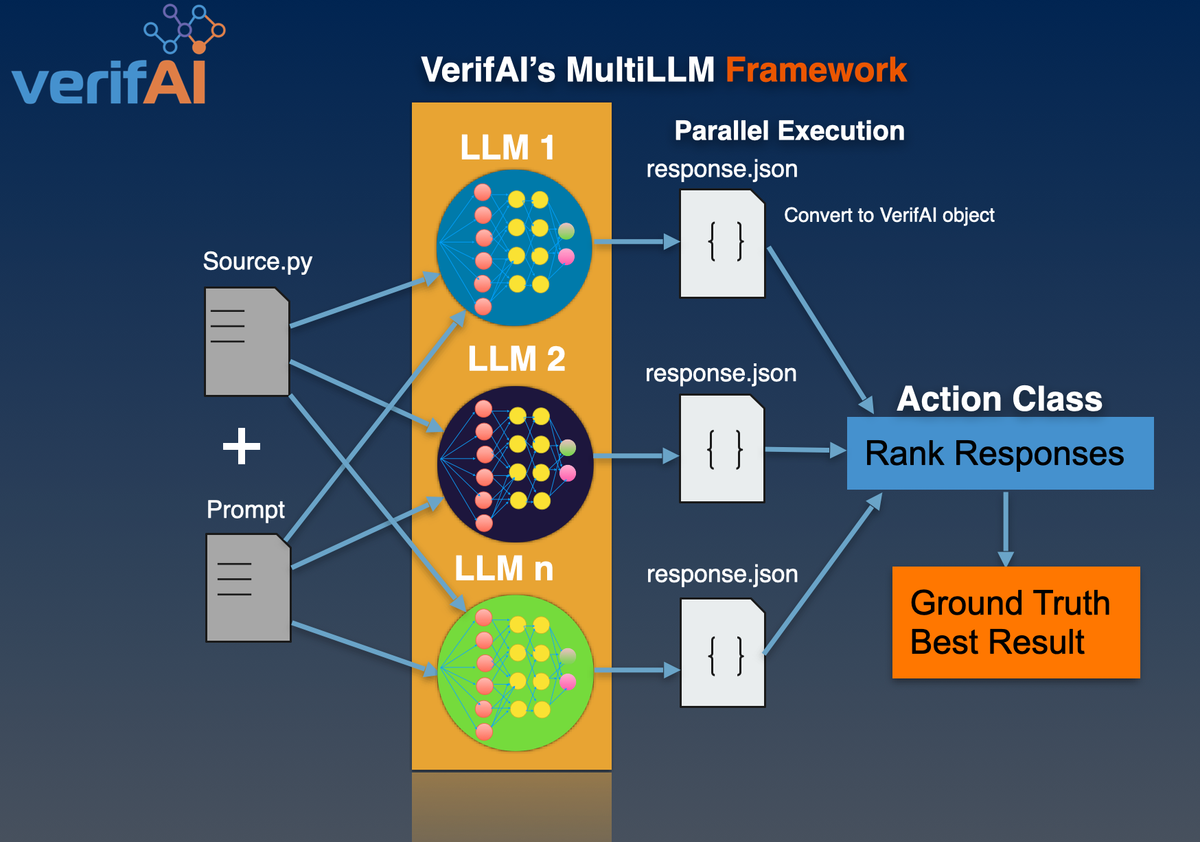
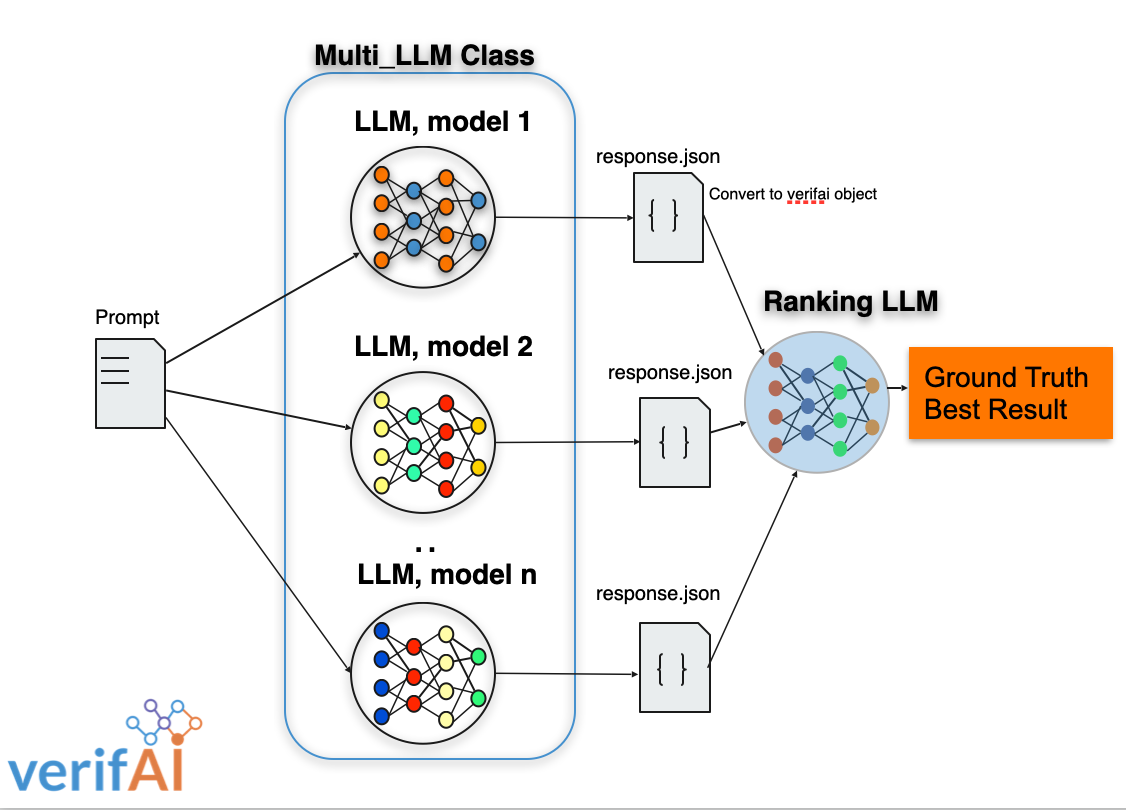
VerifAI's Python MultiLLM framework calls LLMs in parallel and ranks their outputs to find the best results (ground truth).
The first use case is comparing code produced by GPT3,5 and Google-Bard. MultiLLM can be extended to support new LLMs and custom ranking function to evaluate a variety of outputs from LLMs.
The world of natural language processing has witnessed remarkable advancements in recent years, thanks to the proliferation of large language models (LLMs). These LLMs can understand context, generate human-like text, and perform various language-related tasks with astonishing accuracy. However, LLMs can produce incorrect results and hallucinate. That's where the MultiLLM class steps in, offering a solution to concurrently invoke and manage multiple LLMs while efficiently ranking their output to achieve the ground truth.
Unveiling VerifAI's Multi LLM Framework
VerifAI's MultiLLM framework provides a powerful and efficient solution for invoking multiple large language models (LLMs) concurrently and raking their outputs to get the results closest to the ground truth. By leveraging the capabilities of several LLMs together, developers and researchers can address complex tasks more effectively than ever before.
Quick Start
Getting started with the MultiLLM class is straightforward.
Install requirements.txt and the multillm package by executing:
pip3 install -r requirements.txt
pip3 install multillm
In config.json edit "credentials": "<add-your-path>/credentials.json"
config.json File
{
"Config": {
"MultiLLM": {
"rank_callback_file": "example_rank_callback.py",
"llms": [
{
"file": "models/bard.py",
"class_name": "BARD",
"model": "chat-bison@001",
"credentials": "application_default_credentials.json"
},
{
"file": "models/GPT.py",
"class_name": "GPT",
"model": "gpt-3.5-turbo",
"credentials": "/openai/key.json"
}
]
}
}
}
Example google-app-credentials.json
{
"client_id": "123489-6qr4p.apps.googleusercontent.com",
"client_secret": "fx-d3456-tryf0g9f9",
"quota_project_id": "my-llm-training",
"refresh_token": "1-34GFH89KLwe-eft",
"type": "authorized_user"
}
Example openai-credentials.json
{
"organization" : "org-jc8901FDLI0267",
"api_key" : "rt-067FGDiTL834"
}
Execute the following command to run a basic example:
multillm -c config.json -prompt "write a python function to sort an array of a billion integers"
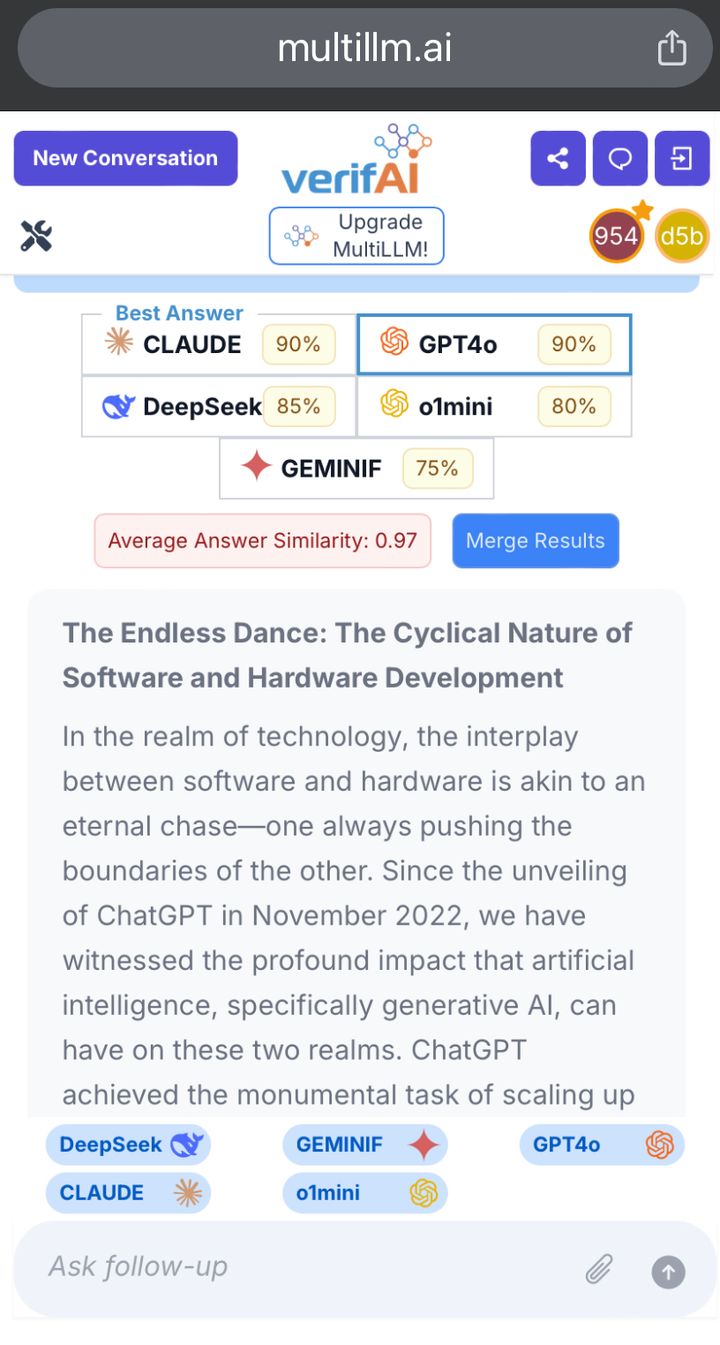
Example Output of ↑ multillm command
multillm response Ranking:
1. GPT
2. BARD
Explanation:
- "GPT's implementation of sorting an array is simpler and more concise. It uses the built-in
sortedfunction in Python, which has a time complexity of O(n log n). On the other hand, BARD's implementation uses the merge sort algorithm, which has a time complexity of O(n log n) as well. However, BARD's implementation is longer and more complex, requiring additional helper functions. Therefore, GPT's implementation is ranked higher"
These example showcases the core functionality of the MultiLLM class, invoking language models concurrently and efficiently processing their responses.
Example 1: Newton's Method
The below examples showcase the command, we ask MultiLLM to generate code from BARD and GPT and to compare the results:
multillm -c config.json -prompt "write a python function to find a root of the function f using Newton's method"
Output of Example 1
loading module bard...
finished loading module bard
registered model BARD <bard.BARD object at 0x10e4e5b70>
loading module GPT...
finished loading module GPT
registered model GPT <GPT.GPT object at 0x10e4e5d20>
loaded llms: {'bard': <module 'bard' from '/Users/Verifai/models/bard.py'>, 'GPT': <module 'GPT' from '/Users/Verifai/models/GPT.py'>}
calling model: BARD
calling model: GPT
model chat-bison@001
BARD Response:
def newton(f, df, x0, tol=1e-6, maxiter=100):
"""
Find a root of the function f using Newton's method.
Args:
f: The function to find a root of.
df: The derivative of f.
x0: The initial guess for the root.
tol: The tolerance for convergence.
maxiter: The maximum number of iterations to perform.
Returns:
The root of f, or None if no root was found.
"""
for i in range(maxiter):
x1 = x0 - f(x0) / df(x0)
if abs(x1 - x0) < tol:
return x1
x0 = x1
return None
GPT Response:
def newton_method(f, f_prime, initial_guess, tol=1e-6, max_iter=100):
"""
Newton's method for finding the root of a function.
Parameters:
f (function): The function for which the root is to be found.
f_prime (function): The derivative of f.
initial_guess (float): The initial guess for the root.
tol (float): The desired tolerance (default 1e-6).
max_iter (int): The maximum number of iterations (default 100).
Returns:
float: The root found by Newton's method, or None if no root is found.
"""
x = initial_guess
for _ in range(max_iter):
fx = f(x)
if abs(fx) < tol:
return x
fpx = f_prime(x)
if fpx == 0:
return None
x -= fx / fpx
return None
MultiLLM Explanation and Ranking for Example 1:
-
"The GPT implementation of the Newton's method function (newton_method) is well-documented with clear parameter explanations and return format. It also includes appropriate input validation checks and handles the case when the derivative is 0. Overall, it is a comprehensive and robust implementation."
-
"The BARD implementation of the Newton's method function (newton) is also well-documented and accepts the necessary parameters. However, it lacks input validation checks, such as when the derivative is 0, and does not provide an explicit return value when no root is found. It can be improved by addressing these limitations."
"Based on these factors, I would rank GPT higher than BARD in terms of the clarity, completeness, and robustness of the implementation."
Example 2: Primes
We ask MultiLLM to write a function to detect prime numbers, and to compare results from BARD and GPT :
multillm -c config.json -prompt "Write me a function to determine whether a number is prime"
Output of Example 2
loading module bard...
finished loading module bard
registered model BARD <bard.BARD object at 0x11e881b70>
loading module GPT...
finished loading module GPT
registered model GPT <GPT.GPT object at 0x11e881d20>
loaded llms: {'bard': <module 'bard' from '/Users/frank/Verifai/repo/verifai-ai/src/verifai/llm/multi_llm/models/bard.py'>, 'GPT': <module 'GPT' from '/Users/frank/Verifai/repo/verifai-ai/src/verifai/llm/multi_llm/models/GPT.py'>}
calling model: BARD
calling model: GPT
model chat-bison@001
BARD Response:
def is_prime(n):
"""Returns True if n is prime, False otherwise."""
if n < 2:
return False
for i in range(2, int(n ** 0.5) + 1):
if n % i == 0:
return False
return True
GPT Response:
def is_prime(number):
if number < 2:
return False
for i in range(2, int(number**0.5) + 1):
if number % i == 0:
return False
return True
MultiLLM Explanation and Ranking for Example 2:
-
"BARD's implementation of the
isprimefunction is identical to GPT's implementation. Both functions check if a number is prime using the same algorithm. Therefore, both LLMs share the same ranking." -
"GPT's implementation of the
isprimefunction is correct and follows the standard algorithm for checking prime numbers. While the implementation is identical to BARD's, it still demonstrates proficiency in coding logic and knowledge of basic mathematical operations."
Example 3: Binary Sort
We ask MultiLLM to write a binary sort function, and to compare results from BARD and GPT :
multillm -c config.json -prompt "write a python function to do a binary sort"
Output of Example 3
loading module bard...
finished loading module bard
registered model BARD <bard.BARD object at 0x1113b1b70>
loading module GPT...
finished loading module GPT
registered model GPT <GPT.GPT object at 0x1113b1d20>
loaded llms: {'bard': <module 'bard' from '/Users/frank/Verifai/repo/verifai-ai/src/verifai/llm/multi_llm/models/bard.py'>, 'GPT': <module 'GPT' from '/Users/frank/Verifai/repo/verifai-ai/src/verifai/llm/multi_llm/models/GPT.py'>}
calling model: BARD
calling model: GPT
model chat-bison@001
BARD Response:
def binary_search(array, target):
left = 0
right = len(array) - 1
while left <= right:
mid = (left + right) // 2
if array[mid] == target:
return mid
elif array[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1
GPT Response:
def binary_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = arr[:mid]
right_half = arr[mid:]
left_half = binary_sort(left_half)
right_half = binary_sort(right_half)
return merge(left_half, right_half)
def merge(left, right):
merged = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] < right[j]:
merged.append(left[i])
i += 1
else:
merged.append(right[j])
j += 1
while i < len(left):
merged.append(left[i])
i += 1
while j < len(right):
merged.append(right[j])
j += 1
return merged
MultiLLM Explanation and Ranking for Example 3:
-
"The GPT solution implements a recursive approach to merge sort. It splits the array into smaller halves, sorts them recursively, and then merges the sorted halves. This approach has a time complexity of O(n log n) and is efficient for large datasets."
-
"The BARD solution implements a binary search algorithm. It searches for a target value in a sorted array by repeatedly dividing the search space in half. This algorithm has a time complexity of O(log n) and is efficient for finding a specific element in a sorted array. The implementation is correct and returns the index of the target if found, or -1 if not found. However, it does not involve ranking or sorting other LLMs, which is the task at hand."
Exploring Use Cases
The MultiLLM class proves its worth across a variety of use cases, enabling users to harness the combined capabilities of multiple LLMs in diverse scenarios. Here are a few scenarios where the application shines:
Complex Query Resolution: When dealing with intricate queries or prompts, using a single LLM might not yield the most accurate or comprehensive results. By leveraging multiple LLMs simultaneously, the MultiLLM class can enhance the quality of responses by aggregating insights from different models.
Action Chains: Often, processing raw LLM outputs directly might not yield the desired results. Action chains provide a mechanism to preprocess LLM responses using a sequence of actions. This empowers users to refine and enhance the output, resulting in more polished and relevant content.
Ranking Aggregation: Combining the outputs of multiple LLMs can be a daunting task. The MultiLLM class includes a Rank class that allows users to modify and rank the combined LLM outputs, making it easier to identify the most relevant information.
Architecture and Components
The architecture of the MultiLLM class is designed for flexibility, modularity, and efficiency. Here's a brief overview of its key components:
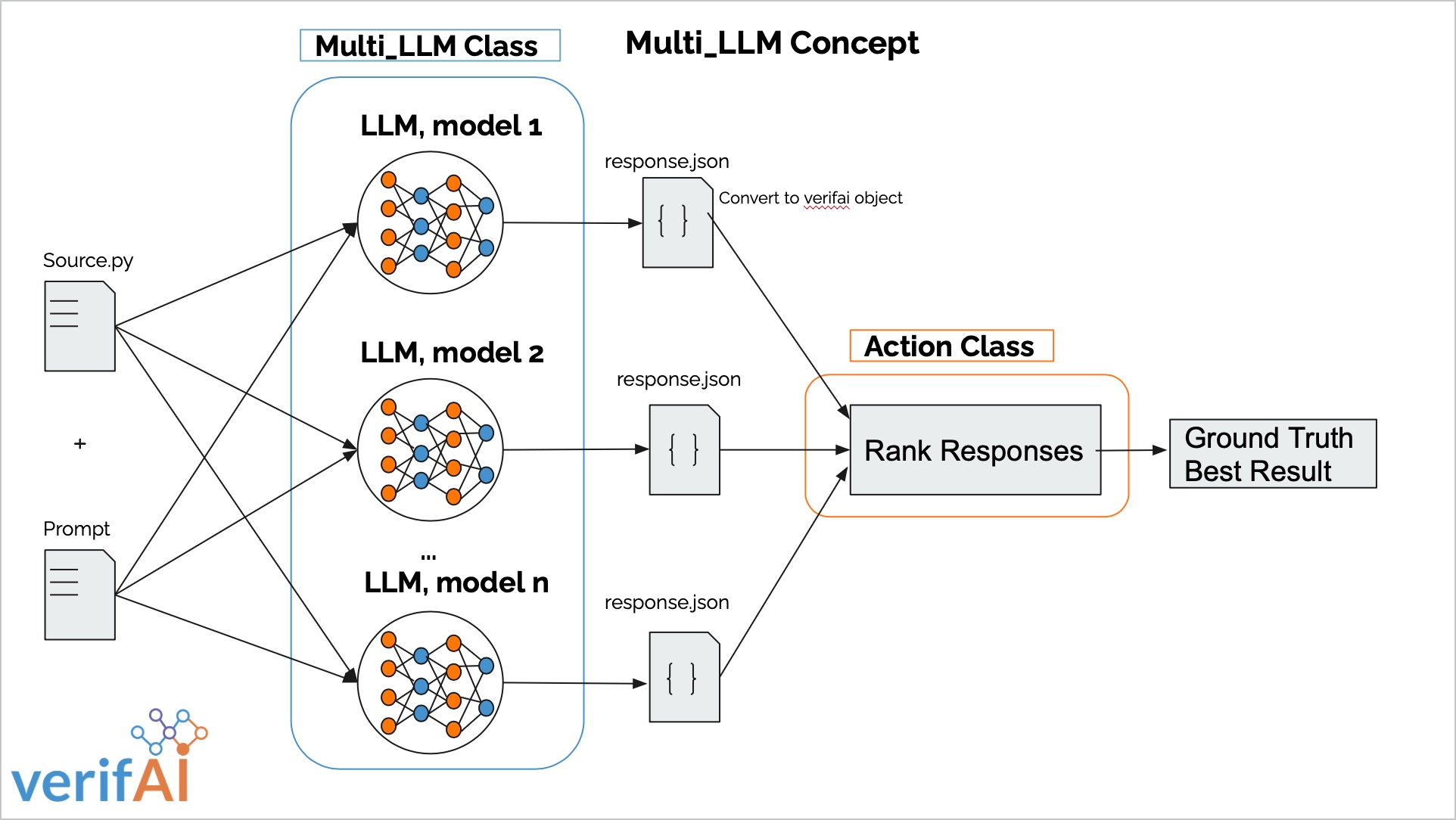
MultiLLM Class
At the heart of the application is the MultiLLM class, responsible for orchestrating the concurrent execution of multiple language models. It allows developers to define and load LLMs from a configuration file, run them in parallel, and process the outputs efficiently.
BaseLLM
The BaseLLM class provides a structured foundation for implementing specific language model classes. It includes essential attributes and methods necessary for interfacing with language models, making it easier to develop and integrate new LLM implementations.
Action Class
The Action class provides a framework for defining actions that can be applied to modify data in a serial manner. These actions can be used to preprocess LLM outputs, such as refining responses, extracting specific information, or applying transformations.
Rank Class
The Rank class, similar to the Action class, allows developers to define actions that operate on the final combined output of multiple LLMs. This class is particularly useful for ranking and aggregating the results from different models.
Contributing to Multi LLM
The VerifAI team welcomes contributions from the community. If you're interested in extending the application's capabilities, adding new language models, or enhancing its existing features, you can do so by extending the models provided in the models directory. Check out the BaseLLM section for guidance on creating your own custom LLM implementations.
Conclusion
The Multi LLM application serves as a testament to the VerifAI team's dedication to optimizing the usage of large language models. By bringing together the power of multiple LLMs, developers can tackle complex language processing tasks with greater efficiency and precision. The application's modular architecture, coupled with the ability to define action chains and rank results, makes it a versatile tool for various use cases. As natural language processing continues to evolve, the MultiLLM class and application is poised to play a pivotal role in driving advancements in the field.