TestGuru Demo - AI Driven Test and Code Co-Pilot for Verilog and Python TestGuru is a VS-Code Plugin, that uses AI to Generate Tests, Write Code, Explain Code, Find and Fix Bugs like no human can. Loading…
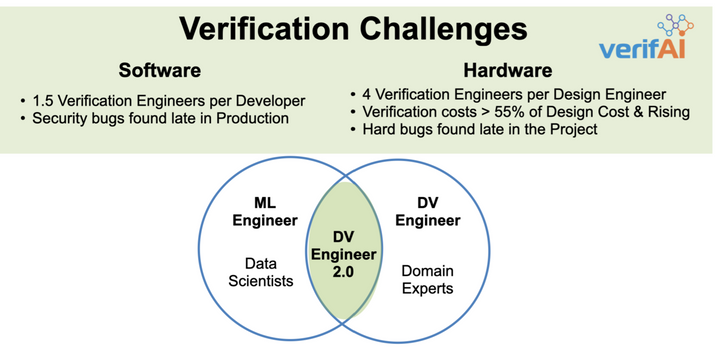
Re-imagining Verification - Verification Engineer 2.0 Verification Challenges The tremendous advances in Integrated Circuit (IC) Design has brought us amazing products over the last decade. These products have permeated into our daily lives in more ways than we had ever imagined and now are an integral part of our day. The advances in IC's
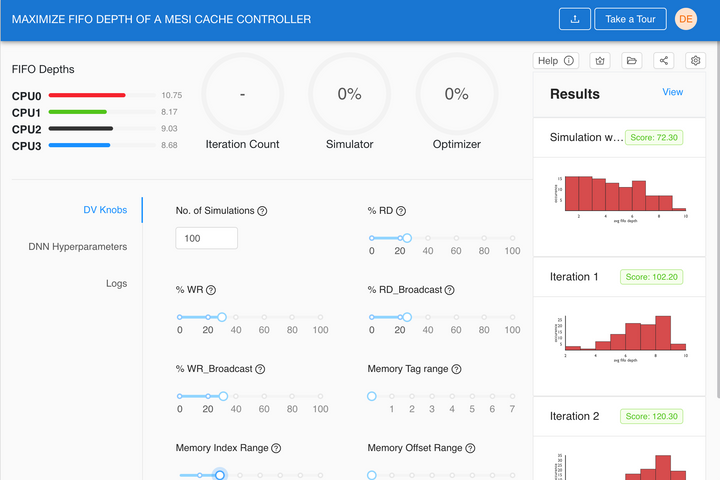
Design Verification Challenge #1 - Maximize FIFO Queues on a 4-CPU Cache Controller Design The Problem The tremendous advances in Integrated Circuit (IC) Design has brought us great products over the last decade. These advances in IC's have also increased the complexity of Design Verification significantly. Design Verification (DV), the process of verifying that an IC functions as intended, takes up more