
Twenty years ago, internet users faced a barrage of search engines; alta vista, infoseek, lycos, excite, yahoo, infospace, askjeeves and of course Google. Today, pretty much only the last one remains, the others fell by the wayside. This ‘winner takes all’ result arises from users understanding which gives the best results combined with no cost to switch between different search engines. Here’s a fun video to show this
Now we have a new barrage of AI powered LLMs or ‘Super Search Engines’ which not only search for text information, but also write computer code, for example; ChatGPT, Mistral, Gemini, Llama, Anthropic, Perplexity and many others. Will history repeat itself, with one Super Search Engine dominating and the remainder fading away?
Each Super Search Engine trains on different data
To answer this question we need to understand differences between the Super Search Engines. Some are trained on whatever web content they find, industry databases, academic white papers, blogs and media sites, irrespective of copyright rules or factual accuracy while others respect legal and privacy boundaries to train their models. Some models are huge, using tens of billions of parameters, while others are much smaller. Given this variance in training data and model size, we believe no single super search engine will give the best responses for all questions or prompts.
Just like Coke and Pepsi, different Super Search Engines will never collaborate with each other
Another insight into why no single Super Search Engine will dominate, is to understand who backs them, namely Microsoft (ChatGPT), Google (Gemini) and Facebook (LLAMA), the largest companies who dominate the internet and ferociously compete against each other. Given this competition and their deep pockets, it is likely each will constantly improve and enhance their offering resulting in ongoing leapfrogging to be the best. Consumers won’t know which is the best Super Search Engine for their specific prompt at any given time as leapfrogging continues.
What does this mean?
Given competition between Super Search Engines combined with the different data upon which each is trained, users may be uncertain if they are getting the best responses for their prompt or they may need to take additional time and effort to compare responses between different Super Search Engines. This knowledge is especially valuable when the prompt is a coding request, since more efficient code can save time and resources.
The Solution
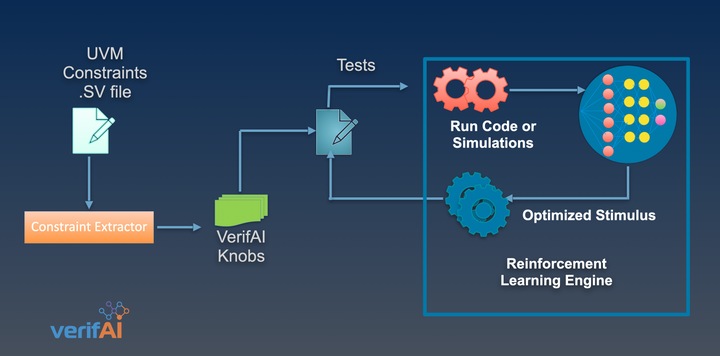
Multillm.ai automatically ranks responses to determine the best Super Search Engine based on a series of parameters and weightings. The parameters differ depending on whether the prompt is a request for text or code.
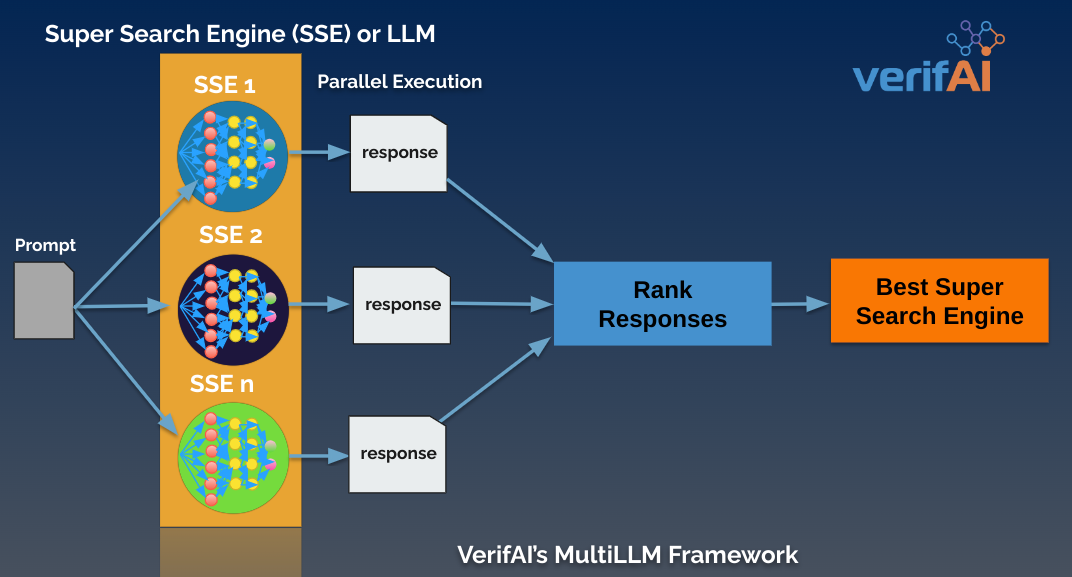
We demonstrate this using the following simple prompts with multillm.ai
Prompt Best Response*
1) How do you measure inflation? LLAMA2
2) What is the best treatment for diabetes? Mistral
3) What are Taylor Swift's most popular songs? Bard
4) Write a tic tac toe game in Python Chat GPT
*Weighted parameters determine 'Best Response', 5 parameters are used to assess code and 6 are used to assess text
From examples above, we see that no single Super Search Engine is best for all prompts.
Try it and let us know if you agree....